
“AI는 어떻게 박사가 되고, 어떻게 정답을 맞힐까요? 단순히 암기하는 것을 넘어 데이터 속의 패턴을 깨우치는 훈련과, 배운 지식을 꺼내 써먹는 추론의 세계를 소개합니다.”
인공지능 학교에서 우등생이 되기 위해 가장 중요한 두 단계가 바로 Training(훈련)과 Inference(추론)입니다. 훈련이 밤새 교과서를 파고드는 ‘공부’ 시간이라면, 추론은 시험장에 들어가 문제를 푸는 ‘실전’ 시간이죠. 이 두 과정이 어떻게 다른지 기술적인 깊이를 더해 알아볼까요?
1. 우리 주변 비유로 이해하기
1) Training (훈련) = ‘수만 권의 문제집을 독파하는 고시생’
데이터로부터 모델의 내부 ‘지능(Weight)’을 만드는 과정입니다.
- Training (훈련): 영어 단어 그대로 ‘학습’, ‘훈련’을 뜻합니다. 수년 동안 대학에서 지식을 쌓으며 패턴을 익히는 것과 같은 과정입니다.
- 공부 방식: 정답이 있는 문제지를 수억 번 반복해서 풀며, 자신이 낸 답과 실제 정답 사이의 오차를 줄여나갑니다.
- 기술적 포인트: 틀린 만큼 ‘반성’하고 그 원인을 찾아 뇌세포(가중치)를 미세하게 조정합니다.
- 특징: 엄청난 슈퍼컴퓨터 자원이 필요하고 시간이 오래 걸립니다.
2) Inference (추론) = ‘현장에 투입된 베테랑 전문가’
훈련된 모델을 실제 서비스에 적용하여 새로운 질문에 답을 내놓는 과정입니다.
- Inference (추론): 이미 배운 지식을 활용해 새로운 문제를 해결한다, 판단한다는 뜻입니다. 시험장에서 문제를 풀거나 실무에서 전문 지식을 발휘하는 단계와 같습니다.
- 실전 방식: 공부는 이미 끝났습니다. 사용자가 “오늘 날씨 어때?”라고 물으면, 훈련 때 익힌 ‘지식 지도’를 따라 즉각적인 답변을 생성합니다.
- 기술적 포인트: . 데이터가 입력에서 출력으로 한 방향으로만 흐르며 결과만 계산합니다.
- 특징: 실시간 응답 속도가 생명이며, 스마트폰 같은 가벼운 기기에서도 돌아가야 합니다.
2. ‘만약에’ 스토리: 왜 훈련과 추론을 꼭 구분할까?
1) Training만 있고 추론이 없다면?
- 상태: AI가 질문을 받을 때마다 처음부터 수억 개의 데이터를 다시 학습해야 합니다.
- 결과: “안녕?”이라고 인사하면 답변을 받기까지 며칠이 걸릴 수도 있습니다. 사실상 서비스가 불가능하죠.
2) Training + Inference 구조라면? (현재의 AI)
- 상태: AI는 먼저 대규모 학습을 마치고 그 결과물(모델)을 ‘지식 저장소’에 저장해둡니다.
- 결과: 사용자가 질문하면 이미 완성된 지식 저장소에서 답을 꺼내오기만 하면 됩니다. 덕분에 ChatGPT나 번역 서비스가 단 몇 초 만에 답변을 줄 수 있는 것이죠.
3. 훈련과 추론의 기술적 측면: 어떻게 하는 거지?
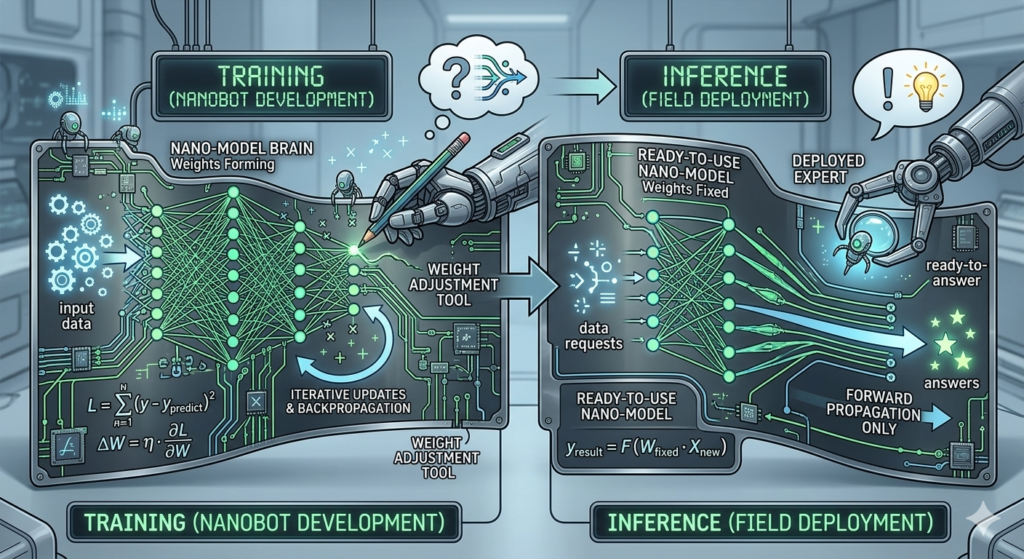
1) 훈련 (Training) 요약
- 데이터 학습 (순전파/앞으로 밀기): 수많은 데이터를 모델에 넣고 일단 답을 내보는 ‘예측 과정’을 진행합니다.
- 오차 수정 (역전파/거꾸로 고치기): 실제 정답과 내 예측을 비교해, 틀린 만큼 뒤에서부터 앞으로 거슬러 올라가며 가중치를 고치는 ‘피드백 학습’을 반복합니다.
- 지능 생성: 이 ‘예측-피드백’ 과정을 수억 번 반복하여 최적의 ‘지식 지도(모델)’를 완성합니다.
- 순전파 (Forward Propagation): 데이터를 입구에서 출구까지 쭉 밀어 넣어 ‘일단 답을 내보는 과정’ 으로 일단 풀어보기에 해당하며 예측 실행(prediction)이라고 볼 수 있다.
- 역전파 (Back Propagation): 결과가 틀린 만큼 출구에서 입구로 거슬러 올라가며 ‘틀린 이유를 찾아 고치는 과정’으로 틀린 이유찾기에 해당하며 오답노트나 피드백(feedback)에 해당한다.
2) 추론 (Inference) 요약
- 지식 활용: 이미 완성된 지식 지도(모델)의 가중치를 단단히 고정(Lock)합니다. 더 이상 배우거나 고치지 않습니다.
- 정답 도출 (순전파 전용): 새로운 데이터를 입구에 넣으면, 학습된 길을 따라 한 방향으로만 슥 통과하여 즉각적인 답을 내놓습니다.
- 서비스 제공: 역전파(피드백 학습) 과정이 없기 때문에 속도가 매우 빠르며, 우리가 ChatGPT를 쓸 때 실시간으로 답변을 받는 실전 단계입니다.
3) 비유로 확인해 보면
- 훈련: 모의고사를 풀고(순전파), 틀린 문제를 오답 노트에 정리하며 실력을 쌓는 것(역전파).
- 추론: 수능 시험장에 들어가서 오답 노트 정리 없이 아는 대로만 빠르게 답을 적어 내는 것(순전파 전용).
4. AI 시대의 핵심 변화: “내 손안의 AI”
최근 AI 기술은 Inference(추론)의 효율성을 높이는 데 집중하고 있습니다.
- 과거: AI를 돌리려면 집채만 한 서버가 필요했습니다.
- 현재: 모델을 가볍게 만드는 경량화 기술과 온디바이스 AI(On-device AI) 덕분에, 이제는 인터넷 연결 없이도 내 스마트폰이나 노트북에서 직접 AI가 추론을 수행하는 시대가 열리고 있습니다.
5. 한눈에 쏙! 짝꿍 비교 표
| 구분 | Training (훈련) | Inference (추론) |
| 역할 | 지식 쌓기 (공부) | 문제 풀기 (실전) |
| 비유 | 수험생 | 전문가 |
| 속도 | 매우 느림 (수개월) | 매우 빠름 (수초) |
| 자원 | 슈퍼컴퓨터/GPU | 스마트폰/NPU/CPU |
| 가중치 | 계속 변함 | 고정됨 |
[Biz-Insight English]
1. 훈련과 추론의 본질적 차이 (공부 vs 실전)
A: In simple terms, how would you define the relationship between AI training and inference? (가장 단순하게 말해서, AI의 훈련과 추론의 관계를 어떻게 정의할 수 있을까요?)
B: Think of Training as the intensive study period where the model builds its intelligence from data, while Inference is the actual exam where it uses that knowledge to answer new questions. (훈련은 모델이 데이터를 통해 지능을 쌓는 집중 학습 시간이고, 추론은 그 지식을 활용해 새로운 질문에 답하는 실제 시험 시간이라고 생각하시면 됩니다.)
2. 기술적 프로세스의 차이 (순전파와 역전파)
A: Does the AI keep learning even during the inference stage? (인공지능이 추론 단계에서도 계속 학습을 하나요?)
B: No, during inference, the model’s weights are locked. It only uses “Forward Propagation” to give quick answers, whereas Training requires “Back Propagation” to constantly fix errors and update its brain. (아닙니다. 추론 중에는 모델의 가중치가 고정됩니다. 추론은 빠른 답을 내기 위해 ‘순전파’만 사용하지만, 훈련은 오차를 수정하고 뇌를 업데이트하기 위해 ‘역전파’ 과정이 필수적입니다.)
3. 실무적 효율성과 온디바이스 AI (속도와 자원)
A: Why is there so much focus on optimizing inference these days? (요즘 왜 그렇게 추론 최적화에 집중하는 것인가요?)
B: Because while Training requires massive supercomputers, Inference needs to be fast and light enough to run on everyday devices like smartphones without a delay. (훈련에는 거대한 슈퍼컴퓨터가 필요하지만, 추론은 스마트폰 같은 일상 기기에서도 지연 없이 돌아갈 만큼 빠르고 가벼워야 하기 때문입니다.)
※ 이 포스팅의 이미지와 일부 설명은 Google Gemini AI와 협업을 통해 제작되었으며, 저자가 직접 내용을 창작,검토하고 편집했습니다