
거대한 거인 vs 똑똑한 꼬마: AI의 미래는 누구의 손에?,
우리는 지금 인공지능이 매일같이 똑똑해지는 시대를 살고 있습니다. 그런데 문득 궁금해집니다. AI는 무조건 데이터를 많이 먹고 덩치가 커야만 똑똑해지는 걸까요? 아니면 사람처럼 핵심만 쏙쏙 골라 배우는 영리한 방법이 있을까요?
오늘은 AI의 지능을 폭발시키는 ‘거인의 법칙(Scaling Law)‘과 실속 있게 승부하는 ‘꼬마 천재(SLM)‘의 흥미진진한 대결을 통해, 미래의 AI가 우리 생활 속에 어떤 모습으로 들어오게 될지 살펴보겠습니다.
1. 우리 주변 비유로 이해하기
1) 스케일링 법칙 (Scaling Law) = ‘엄청난 공부벌레 거인’
데이터를 무조건 많이 먹을수록 더 똑똑해진다는 믿음이에요.
- 공부 방식: 세상에 있는 모든 책을 다 읽으려고 해요. 책이 1,000권일 때보다 10,000권일 때 훨씬 더 똑똑해진다고 믿죠.
- 실제 상황: “모든 데이터를 다 집어넣어! 그러면 스스로 지능이 폭발(창발)할 거야!”라고 외쳐요.
- 특징: 몸집이 엄청나게 커서 공부하는 데 돈이 많이 들지만, 일단 공부가 끝나면 모르는 게 없는 만능 박사가 돼요.
2) 소형 모델 (SLM) = ‘핵심만 콕 집어 공부하는 꼬마 천재’
무조건 많이 읽는 것보다, 좋은 책을 제대로 읽는 효율성을 중요하게 생각해요.
- 공부 방식: “세상 모든 책을 다 읽을 필요는 없어!”라고 말하며, 꼭 필요한 핵심 요점 정리만 반복해서 완벽하게 공부해요.
- 실제 상황: 스마트폰이나 개인 컴퓨터처럼 작은 곳에서도 쌩쌩 돌아갈 수 있게 아주 가볍게 만들어져요.
- 특징: 몸집은 작지만 특정 주제(수학, 법률, 코딩 등)에서는 거인 못지않게 똑똑해요.

2. ‘만약에’ 스토리: 왜 이 둘이 싸울까?
1. 거인이 이기는 경우 (Scaling Law)
- 상황: 돈과 컴퓨터가 엄청나게 많을 때!
- 결과: 인간이 가르쳐주지 않은 창의적인 능력까지 스스로 깨우쳐요. ChatGPT 같은 대장 AI가 바로 이 방식이죠.
2. 꼬마 천재가 이기는 경우 (SLM)
- 상황: 인터넷이 안 되는 곳이나, 돈을 아끼고 싶을 때!
- 결과: 거인을 부르는 데 드는 전기료의 1/100만 쓰고도 똑똑한 답변을 내놓아요. 우리 집 가전제품이나 휴대폰 속에 쏙 들어갈 수 있죠.
3. 잠깐! 이름의 유래: 왜 ‘스케일링’이고 ‘SLM’일까?
- 스케일링(Scaling): ‘규모를 키운다’는 뜻이에요. 풍선에 바람을 넣듯 데이터와 컴퓨터를 계속 키우는 것이 핵심이죠.
- SLM(Small Language Model): 말 그대로 ‘작은 언어 모델’이에요. 덩치를 줄이는 대신 알고리즘의
지혜를 짜내어 실속을 챙겼다는 뜻입니다. 아래 그림은 SLM이 좋은 성과를 냈을 때 상황입니다.

4. 필살기 비교: 힘의 대결 vs 지혜의 대결
- 스케일링 법칙의 필살기: “압도적 물량” – 수조 개의 데이터를 쏟아부어 지능의 한계를 돌파해요.
- SLM의 필살기: “데이터 다이어트” – 나쁜 데이터는 버리고 진짜 좋은 데이터만 골라 배워서 작지만 강하게 만들어요.
5. 한눈에 쏙! 짝꿍 비교 표
| 구분 | 스케일링 법칙 (거인의 힘) | SLM (꼬마의 지혜) |
| 핵심 무기 | 엄청난 데이터의 양 | 똑똑한 학습 알고리즘 |
| 장점 | 모르는 게 없는 만능 지능 | 빠르고, 싸고, 가벼움 |
| 단점 | 돈과 전기가 너무 많이 듦 | 아주 복잡한 추론은 힘들 수 있음 |
| 어울리는 곳 | 거대 기업의 서버 | 스마트폰, 가전제품, 내 컴퓨터 |
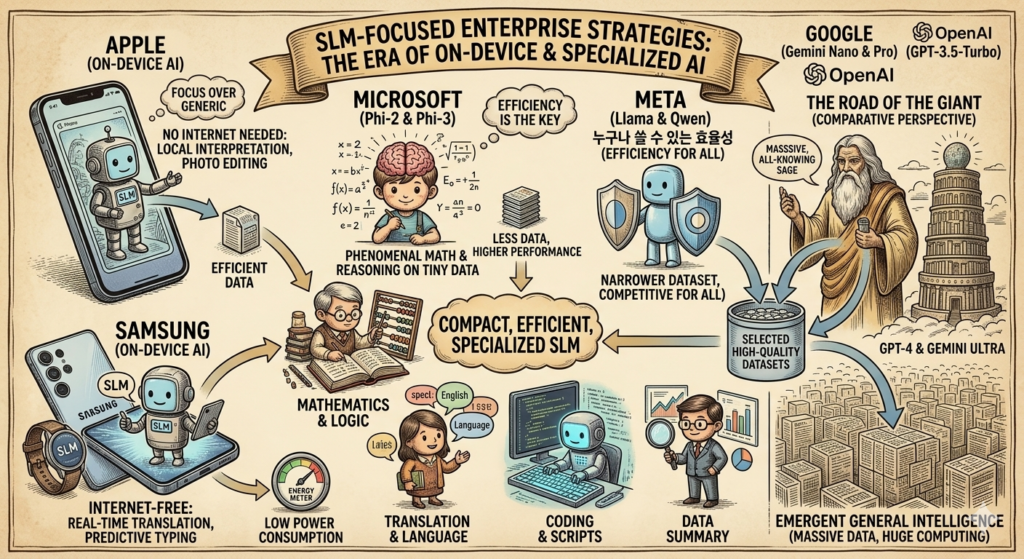
6. ‘어떤 회사가 무엇을 하고 있을까?’ (기업별 전략)
지금 전 세계 빅테크 기업들은 이 두 가지 길 중 하나를 선택하거나, 두 마리 토끼를 모두 잡으려 노력하고 있습니다.
- 오픈AI (OpenAI) & 구글 (Google): 주로 ‘거인의 길’을 걷습니다. ‘GPT-4’나 ‘Gemini Ultra’처럼 엄청난 양의 데이터와 슈퍼컴퓨터를 쏟아부어, 인간과 거의 흡사한 만능 AI를 만드는 데 집중합니다.
- 메타 (Meta): ‘라마(Llama)’라는 모델을 통해 ‘누구나 쓸 수 있는 효율성’을 강조합니다. 덩치는 줄이면서도 성능은 거인에 육박하는 모델을 만들어 전 세계에 공개하고 있죠.
- 마이크로소프트 (Microsoft): 최근 ‘파이(Phi)’라는 아주 작은 모델을 발표하며 ‘꼬마 천재’ 전략에 집중하고 있습니다. 아주 적은 데이터만으로도 수학 문제를 기가 막히게 푸는 모델을 만들어 세상을 놀라게 했습니다.
- 애플 & 삼성전자: ‘온디바이스 AI’를 위해 꼬마 천재(SLM)가 꼭 필요합니다. 스마트폰 안에서 인터넷 연결 없이도 통역이나 사진 편집을 빠르게 처리하기 위해 소형 모델 기술을 적극 도입하고 있습니다.
[영어 공부 코너]
- 일상생활
- A: Does an AI always need more data to be smarter? (AI는 똑똑해지려면 항상 더 많은 데이터가 필요해?)
- B: Not necessarily! Efficiency is becoming more important these days. (꼭 그렇진 않아! 요즘은 효율성이 더 중요해지고 있거든.)
- IT 비즈니스 현장
- A: Should we focus on Scaling Law or SLM? (스케일링 법칙과 소형 모델 중 어디에 집중해야 할까요?)
- B: It depends on the goal. Scaling Law is for power, and SLM is for efficiency. (목표에 따라 달라요. 성능은 스케일링 법칙, 효율은 SLM이죠.)
※ 이 포스팅의 이미지와 일부 설명은 Google Gemini AI와 협업을 통해 제작되었으며, 저자가 직접 내용을 창작, 검토하고 편집했습니다.