
인공지능의 진화 속도가 무서울 정도입니다. 여기서 우리가 주목해야 할 지점은 ‘규모의 경제’인가, 아니면 ‘학습의 지혜’인가 하는 문제입니다. 무조건적인 물량 공세가 정답일지, 아니면 작지만 강한 효율성이 미래를 바꿀지, 그 열쇠를 쥐고 있는 핵심 개념을 살펴봅니다.
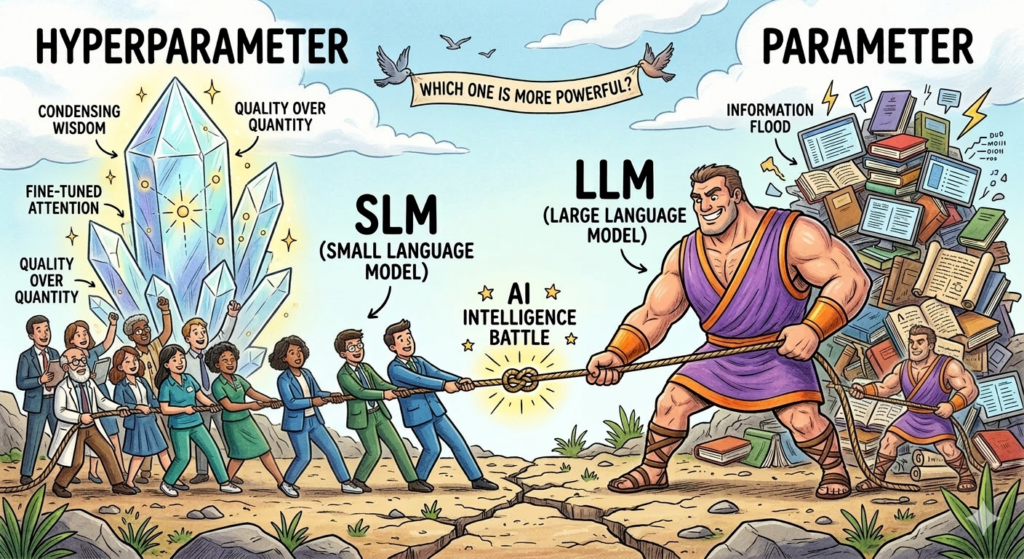
오늘은 이 대결의 중심에서 AI의 뇌세포 역할을 하는 ‘파라미터(Parameter)’를 주인공으로 세워보려 합니다. 파라미터가 수조 개에 달하는 거대한 거인(LLM)과, 사람이 정해준 정교한 하이퍼파라미터(Hyperparameter) 전략으로 무장한 똑똑한 꼬마(SLM). 과연 누가 승자가 될까요?
1. 일상생활에서 어떤 뜻?
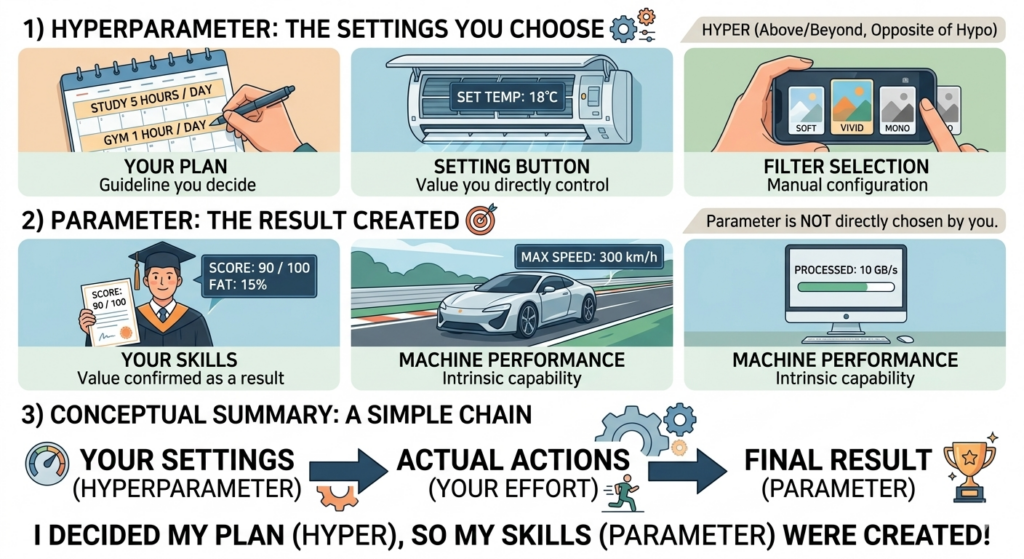
1) 파라미터 (Parameter) = “만들어진 결과물”
이것은 내가 직접 숫자를 고치는 게 아니라, 나의 행동이나 시스템을 통해 나중에 확인하게 되는 값입니다.
- 나의 실력: “수능 90점”, “체지방 15%”처럼 결과적으로 내 몸과 머리에 남겨진 수치입니다.
- 기계의 성능: 내 차의 “최고 속도”나 내 컴퓨터의 “실제 처리 속도”처럼 그 물건이 가지고 있는 능력치입니다.
2) 하이퍼파라미터 (Hyperparameter) = “내가 정한 세팅”
이것은 어떤 결과를 만들기 위해 내가 시작 전부터 직접 결정하고 입력하는 값입니다.
- 하이퍼(Hyper)는 기준보다 ‘위에(Above)’ 있거나 한계를 ‘넘어선(Beyond)’ 상태를 뜻으로 하이포(Hypo)의 반대말입니다.
- 나의 계획: “하루 5시간 공부”, “매일 1시간 운동”처럼 내가 의지를 가지고 미리 정한 가이드라인입니다.
- 조작 버튼: 에어컨의 “희망 온도 설정”이나 카메라의 “필터 선택”처럼 내가 직접 손으로 만지는 설정값입니다
- “내가 정한 ‘계획(하이퍼)’대로 움직였더니, 나의 ‘실력(파라미터)’이 만들어졌다!”
2. AI에서 (하이퍼)파라미터가 뭐죠?
1) 파라미터 (Parameter) = AI가 쌓아 올린 ‘지식의 장서량’
AI가 학습을 통해 스스로 만들어내는 지능의 수치들입니다. 이 수치가 많아질수록 AI가 가진 정보의 깊이가 달라집니다.
- 대형 도서관의 길: “지능(파라미터)을 수조 개로 늘려 모든 책을 소장하자!” 수만 대의 컴퓨터를 동원해 엄청난 규모의 파라미터를 구축한 모델입니다.
- 요점 정리의 길: “지능(파라미터)은 적어도 좋아, 대신 한 권의 책을 완벽히 이해하자!” 파라미터 숫자는 적지만 알짜배기 지식만 담은 효율적인 모델입니다.
- 비유: 공부한 결과로 뇌세포에 새겨진 ‘진짜 실력’입니다. 사람이 억지로 숫자를 바꿀 수 없는 학습의 결과물이죠.
2) 하이퍼파라미터 (Hyperparameter) = 사람이 설계한 ‘학습 커리큘럼’
AI가 공부를 시작하기 전, 사람(사용자)이 미리 정해주는 지침입니다. 상위에서 규칙을 제어하는 존재같은 것입니다.
- 역할: “도서관아, 너는 책이 많으니 분류를 아주 꼼꼼하게 해”, “노트야, 너는 짧은 시간에 100번 반복해서 외워!”라고 공부법을 정해주는 것입니다.
- 비유: 실력을 쌓기 위해 내가 세운 ‘공부 계획표’입니다. 이 커리큘럼이 정교해야 적은 파라미터로도 천재적인 결과를 낼 수 있습니다.
3. 주요 AI 모델 체급별 비교 (2026년 기준)
| 체급 (Scale) | 모델명 (Example) | 파라미터 수 (추정) | 핵심 강점 (Strategy) | 도서관 비유 (Analogy) |
| 초거대형 (XL) | GPT-4o / Gemini 1.5 | 약 1.5조 ~ 2조 개 | 방대한 데이터 통합 능력 | 모든 지식을 갖춘 국가대표 대형 도서관 |
| 중형 (Medium) | Claude 3.5 Opus | 약 2,000억 ~ 3,000억 개 | 정교한 추론과 창의적 답변 | 소량의 데이터로 정답을 찾는 천재 연구원 |
| 중형 (Medium) | Llama 3.1 (70B) | 700억 개 | 기업용 서버 최적 가성비 | 실속 있는 지식을 갖춘 지역 거점 도서관 |
| 소형 (SLM) | Llama 3.1 (8B) | 80억 개 | 빠른 반응 속도, 온디바이스 | 작지만 필요한 것만 모은 알찬 개인 서재 |
| 소형 (SLM) | Phi-3 Mini | 38억 개 | 특정 분야 성능 극대화 | 정교한 설계로 승부하는 포켓용 전문 서적 |
4. ‘만약에’ 스토리: 파라미터의 밀도가 운명을 가른다!
1) 파라미터가 수조 개일 때 (정보의 대홍수)
- 상황: 세상의 모든 책을 갖춘 거대 디지털 아카이브입니다.
- 파라미터 숫자를 압도적으로 늘리면, 마치 세상의 모든 이치를 깨달은 듯한 ‘창발적 지능’이 나타납니다.
- 결과: 무엇을 물어봐도 척척 대답하는 만능 박사가 되지만, 도서관을 유지하는 데 엄청난 전기료와 관리비가 듭니다.
2) 파라미터는 적지만 하이퍼파라미터가 날카로울 때 (지혜의 응축)
- 상황: “파라미터는 적지만, 사람의 노련한 공부 전략(하이퍼파라미터)으로 아주 밀도 있게 학습시켰어!”
- 결과: 덩치는 대형 도서관의 1/100도 안 되지만, 정교한 설계로 필요한 정보가 다 있는 전문 서재입니다. 사람이 정한 영리한 공부법 덕분에 적은 데이터로도 천재적인 연구 결과를 냅니다.
- 특정 질문에는 누구보다 빠르고 정확한 해답을 내놓습니다. 내 손안의 스마트폰에서도 쌩쌩 돌아가는 실속형 지능이 되죠.

5. 데이터 다이어트의 비밀: 적게 배워도 잘 할 수 있나요?
무조건 많은 데이터를 읽는 것보다, 적은 양의 데이터를 읽는 AI가 더 정교한 답변을 내놓는 데에는 다음과 같은 비결이 숨어 있습니다
- 데이터의 ‘질’이 결정타 (Quality over Quantity) 인터넷의 잡다한 정보 대신 전문가가 검수한 ‘깨끗하고 수준 높은 데이터’만 골라 학습합니다. 1만 권의 잡지보다 1권의 명저를 깊게 읽는 것이 더 높은 지능을 만드는 원리와 같습니다.
- 특정 분야에 집중하는 ‘전문화’ (Domain Specialization) 세상 모든 것을 알려고 하기보다 수학, 법률, 코딩 등 특정 영역에만 파라미터(지능 세포)를 집중시킵니다. 에너지가 한곳으로 모이기 때문에 해당 분야만큼은 거대 모델보다 더 날카로운 전문성을 갖게 됩니다.
- 핵심에 집중하는 ‘어텐션’ 기술 (Fine-tuned Attention) 모든 단어를 똑같이 취급하지 않고 문맥상 가장 중요한 정보에만 강하게 반응하도록 훈련합니다. 핵심 요약 노트를 만들 때 중요한 부분에만 형광펜으로 밑줄을 긋는 것과 같은 이치입니다.
- 반복 학습을 통한 ‘응축된 지능’ (Deep Iterative Learning) 데이터가 적은 대신 그 내용을 수천 번 반복해서 완벽하게 소화합니다. 이 과정에서 파라미터들 사이의 연결이 훨씬 더 촘촘하고 단단해지며, ‘좁지만 아주 깊은 추론 능력’이 만들어집니다.
6. 핵심 요약: 특화(Niche)와 하이퍼파라미터는 어떻게 다른가?
“특화된 모델이면 당연히 하이퍼파라미터가 좋은 것 아닌가?”라고 혼동하기 쉽지만 이 둘은 엄격히 다릅니다.
- 싸움터 vs 필살기: 특화(Niche)는 ‘의학’이나 ‘법률’처럼 싸울 장소를 정하는 것이고, 하이퍼파라미터는 그곳에서 승리하기 위해 연마한 필살기(학습 전략)입니다.
- 공간 vs 운영: 특화가 ‘전문 매장을 여는 것’이라면, 하이퍼파라미터는 그 좁은 매장을 백화점보다 수익성 높게 만드는 ‘운영의 묘’입니다.
- 범위 vs 지능: 단순히 범위를 좁혔다고(특화) 지능이 좋아지는 건 아닙니다. 사람이 설계한 정교한 지침(하이퍼파라미터)이 더해져야 비로소 ‘압축된 지능’이 완성됩니다.
7. 한눈에 쏙! 짝꿍 비교 표
| 구분 | 파라미터 (Parameter) | 하이퍼파라미터 (Hyperparameter) |
| 비유 | 공부해서 쌓은 ‘진짜 실력’ | 실력을 쌓기 위한 ‘공부 계획’ |
| 결정 주체 | AI가 스스로 학습하며 습득 | 사람(설계자)이 미리 결정 |
| 역할 | 지식의 깊이와 장서량 결정 | 학습의 효율과 속도 조절 |
| 비즈니스 | 규모의 경제 (거대 모델) | 운영의 경제 (효율 모델) |
[Biz-Insight English]
1. 모델의 체급과 실질적 성능 (Parameter)
A: Why is the industry so obsessed with the number of parameters in a model? (왜 업계에서는 모델의 파라미터 수에 그토록 집착하는 걸까요?)
B: Parameters represent the “knowledge capacity” of an AI, similar to the number of books in a library; more parameters generally lead to deeper intelligence and “emergent abilities.” (파라미터는 AI의 ‘지식 수용량’을 나타내며 도서관의 장서 수와 비슷합니다. 일반적으로 파라미터가 많을수록 더 깊은 지능과 ‘창발적 능력’으로 이어지기 때문입니다.)
2. 효율적인 학습을 위한 설계자의 역할 (Hyperparameter)
A: Can a smaller model ever compete with a giant LLM? (소형 모델이 거대 언어 모델과 경쟁하는 것이 가능할까요?)
B: Yes, if we design a sharp “curriculum” using hyperparameters. While parameters are the learned results, hyperparameters are the human-defined settings that control how efficiently the AI learns. (네, 하이퍼파라미터를 이용해 날카로운 ‘커리큘럼’을 설계한다면 가능합니다. 파라미터가 학습된 결과물이라면, 하이퍼파라미터는 AI가 얼마나 효율적으로 배울지를 제어하는 인간이 정의한 설정값입니다.)
3. 비즈니스 가성비와 전략적 선택 (Optimization)
A: Is it always better to have more parameters for our enterprise AI? (우리 기업용 AI에 파라미터가 많을수록 항상 좋은 것일까요?)
B: Not necessarily. Increasing parameters boosts performance but also raises costs. By fine-tuning hyperparameters, we can create a “lean and mean” model that delivers high-quality insights at a fraction of the price. (꼭 그렇지는 않습니다. 파라미터를 늘리면 성능은 좋아지지만 비용도 상승합니다. 하이퍼파라미터를 정교하게 조정함으로써, 훨씬 저렴한 비용으로 고품질의 통찰력을 제공하는 ‘작지만 강한’ 모델을 만들 수 있습니다.)
※ 이 포스팅의 이미지와 일부 설명은 Gemini AI와 협업을 통해 제작되었으며, 저자가 직접 내용을 창작, 검토하고 편집했습니다.