
Do you know the architecture behind the artificial intelligence revolution that has completely reshaped our modern digital landscape? The breakthrough that shifted AI from a simple algorithmic calculator into a human-like conversational engine is a deep learning framework called the Transformer.
Before this revolutionary model arrived in the artificial intelligence ecosystem, the undisputed scholar of Natural Language Processing (NLP) was the Recurrent Neural Network (RNN). If we look closely at how these two frameworks operate, an RNN learns language by meticulously writing down a text one single character or word at a time, whereas a Transformer scans an entire page simultaneously in a single glance. Today, we will use our analytical microscope to examine how these two architectures differ in how they process, understand, and reconstruct our world.
1. Everyday Metaphors: Understanding the Learning Mechanics
To demystify these complex computational frameworks without getting lost in deep data science syntax, let’s look at two simple, relatable analogies involving human information processing.
1) RNN = The Hardworking but Forgetful Scribe
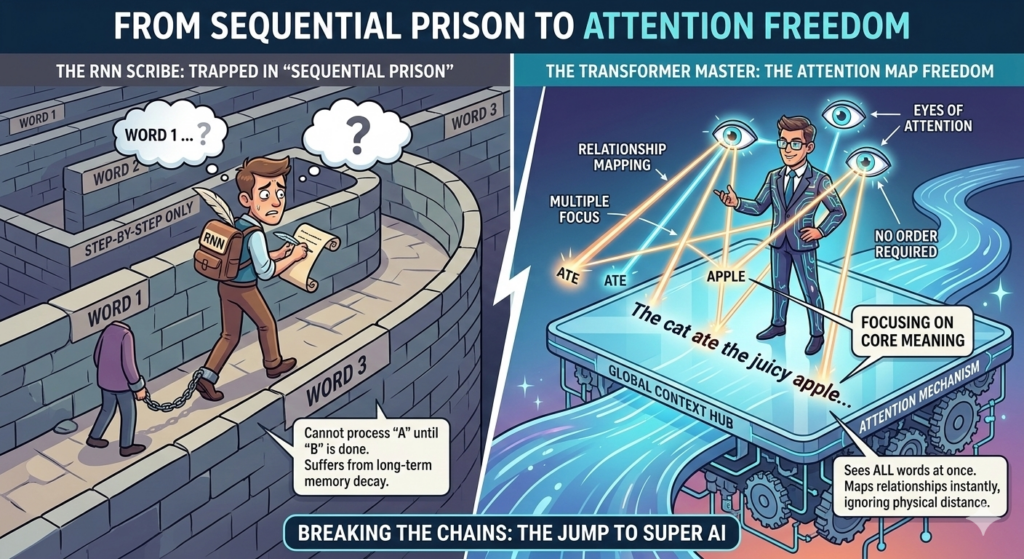
Imagine a diligent administrative secretary who has been tasked with transcribing an exceptionally long speech in real time. Because of a strict procedural rule, this scribe is only allowed to listen to and write down one single word at a time, moving sequentially from left to right. To maintain the overarching context, the scribe must constantly hold the historical memory of the previous words in their head while writing down the current word.
In computer science, this is exactly why it is called a Recurrent Neural Network; it cycles past data into current computational decisions.
However, a major human flaw emerges over time. If you present this model with an extensive paragraph, such as: “I had a deliciously crisp apple for breakfast this morning along with my coffee, but by the time the long afternoon meeting concluded, that fruit was completely…” By the time the sequential scribe reaches the end of the sentence, the historical memory layer has degraded. The scribe becomes confused, struggling to remember whether the speaker ate an apple or a pear. In data science, this structural limitation is known as the Long-Term Dependency Problem. It means that while the sequential order of words is preserved, the model loses its grip on long-range context.
2) Transformer = The All-Seeing Visionary Genius
Now, imagine a highly advanced speed-reader who completely disregards sequential limitations. Instead of reading a sentence word-by-word from start to finish, this reader snaps a high-resolution digital photograph of the entire page all at once. Once the page is captured, the reader draws a complex web of mental arrows connecting every single word to every other word on the page, instantly calculating how they relate to one another regardless of how far apart they sit.
The mathematical technology that allows the Transformer to achieve this is called the Attention Mechanism (specifically, Self-Attention).
When faced with a long narrative, the Transformer does not guess or lose its place. If a sentence reads: “The cinematic masterpiece we watched at the theater last night was incredibly gripping, and I was especially moved by how beautifully the main actor’s performance captured…” the model instantly links the word “performance” back to “cinematic masterpiece” across a massive block of text. It mapping the global context of the entire document simultaneously, ensuring no critical connections are lost.

2. The “What If” Scenarios: The Great Paradigm Shift
To understand why the global technology sector completely abandoned older sequential architectures in favor of the Transformer model, let’s analyze how these frameworks perform under intense enterprise workloads.
Scenario A: Operating Exclusively in an RNN Infrastructure
- The Reality: A major language processing platform continues to run its translation services using an older RNN architecture because it has a long, established history in text processing.
- The Result: The platform hits an impenetrable scaling wall. Because an RNN must process word t before it can move on to word t+1, it cannot break up a sentence to distribute it across multiple computer processors. This total lack of Parallel Processing means that as enterprise data sets grow larger, the system slows down dramatically. The computers essentially go on strike because they cannot handle the massive computational traffic sequentially.
Scenario B: Migrating to a Transformer-Based Infrastructure
- The Reality: A tech enterprise upgrades its engineering pipeline to a Transformer architecture, pouring millions of words into the system simultaneously.
- The Result: The model achieves rapid training speeds. Because the architecture maps relationships across an entire document at once, the workload can be split up and processed simultaneously across thousands of high-performance Graphics Processing Units (GPUs). This massive leap in computing speed paved the way for the modern Hyper-Scale AI era, making the creation of Large Language Models (LLMs) like ChatGPT possible. (In fact, the “T” in ChatGPT stands explicitly for Transformer!)
3. Etymology and Origins: The Alchemy of Data Transformation
While the term might evoke images of sci-fi shape-shifting robots, the word “Transformer” describes a deep, fundamental process in computer science.
The architecture is named for its unparalleled ability to transform data shapes. It ingests raw human language and immediately maps it into a highly optimized, multi-dimensional mathematical coordinate map (embeddings). Once the computer manipulates these numerical matrices to calculate meaning, the system transforms those coordinates back into fluid, contextually accurate human speech.
Rather than just translating words literally, it acts as a digital alchemist—completely restructuring the underlying format of data to find its absolute core meaning before generating a response.
4. Escaping the Sequential Prison: The Power of Self-Attention
To see why the Transformer is a revolutionary milestone in deep learning, let’s explore how it escapes the architectural limitations of older models.
Traditional neural networks were trapped in a sequential sequence: A leads to B, B leads to C, and C leads to D. The Transformer broke out of this rigid structure by replacing step-by-step processing with a comprehensive map of structural relationships. Consider this example sentence:
“John walked into a local convenience store yesterday afternoon, bought a fresh, delicious pastry, and happily ate it while walking to his university campus.”
If an AI wants to understand this sentence, it must figure out exactly what the word “it” refers to.
- The Sequential Approach (RNN): The network plods through the sentence word by word. By the time it reaches the word “it,” the historical memory of “pastry” has faded, and the model struggles to determine if “it” refers to the convenience store, John, or the university.
- The Attention Approach (Transformer): The system evaluates the entire sentence at once. Through the self-attention mechanism, it runs calculations across all tokens simultaneously and discovers that “it” shares its strongest mathematical connection with “pastry.”
By identifying where to focus its attention within a document, the Transformer captures the true context of human communication.
5. Side-by-Side Comparison: Engineering Parameters
To help your engineering teams evaluate these two landmark models during infrastructure planning or model selection, let’s look at their core traits side-by-side:
| Category | RNN (The Sequential Legacy) | Transformer (The Parallel Standard) |
|---|---|---|
| Data Processing Method | Sequential; processes data word-by-word in order. | Parallel; processes entire text blocks simultaneously. |
| Context Retention Capacity | Low; suffers from data loss over long text sequences. | Exceptionally High; retains long-range context via Attention. |
| Training Speed & Efficiency | Slow; restricted to single-core computing pipelines. | Ultra-Fast; optimized for high-performance GPU clusters. |
| Primary Industry Use Case | Legacy text translation and simple voice recognition. | Foundation for LLMs, advanced translation, and generative art. |
6. The Enterprise Ecosystem: Who Implements This Technology?
Because the Transformer architecture is incredibly versatile, several key engineering roles leverage this framework to build modern, production-grade AI platforms:
- Language Model Engineers: These specialists design the core multi-layered Transformer architectures that power advanced conversational AI engines like ChatGPT and Claude.
- Localization & Neural Translation Experts: They use the global context tracking of self-attention to build translation services that understand regional idioms, culture, and industry terminology rather than just translating words literally.
- Multimodal Integration Specialists: These innovators expand the Transformer model beyond text, using it to map the relationships between written descriptions, images, and video frames to drive the next wave of generative media.
7. One-Sentence Summary
While an RNN is a meticulous scribe that processes data step-by-step until it loses its place in long text, a Transformer is an analytical genius that evaluates an entire document at once, mapping relationships to capture true context.
Conclusion: Key Takeaways for Today’s Tech Strategy
Adopting modern machine learning architectures is essential for building scalable applications and maintaining a competitive edge in today’s market.
- Deprecate Sequential Legacy Infrastructure: If your business applications still rely on traditional RNN architectures for text mining or customer support routing, plan a migration to Transformer-based micro-models. The leap in accuracy and context retention directly impacts the user experience.
- Maximize Compute Efficiency via Parallelization: Leverage the parallel processing nature of Transformers to optimize your cloud compute spending. By distributing training workloads across modern GPU clusters, you can drastically cut down on training times.
- Prepare for a Multimodal Future: The Transformer is no longer just a tool for text. Because its underlying mathematics maps relationships between any data inputs, you can use it to find patterns across financial charts, visual records, and acoustic streams, breaking down data silos across your enterprise.
AI Disclosure: Created in collaboration with Google Gemini. All core content was authored, reviewed, and edited by the author.